The Problem of Scale and the Fragility of Design
I recall a chilly morning in March 2019 when I oversaw the installation of a 12-inch polymeric capture array at a midsize genomics facility in Cambridge; the ambition was great, yet the first run yielded a 38% loss in mapped reads and a week’s delay in deliverables (that setback still informs my judgment). Early in that episode we had deployed stereo-seq large chip designs, and the failure illuminated common flaws in large stereo seq transcriptomics workflows: inconsistent spot size, poor barcode array layout, and variable capture efficiency. A clinical lab scenario—one month of stalled throughput, 20 failed samples, and client penalties—posed a clear practical question: what design faults most often convert scale into fragility, and how may they be remedied? I write from over fifteen years trading and consulting in B2B supply chains for lab consumables, and I speak plainly: I have seen the same ergonomic missteps and engineering oversights repeat, again and again.
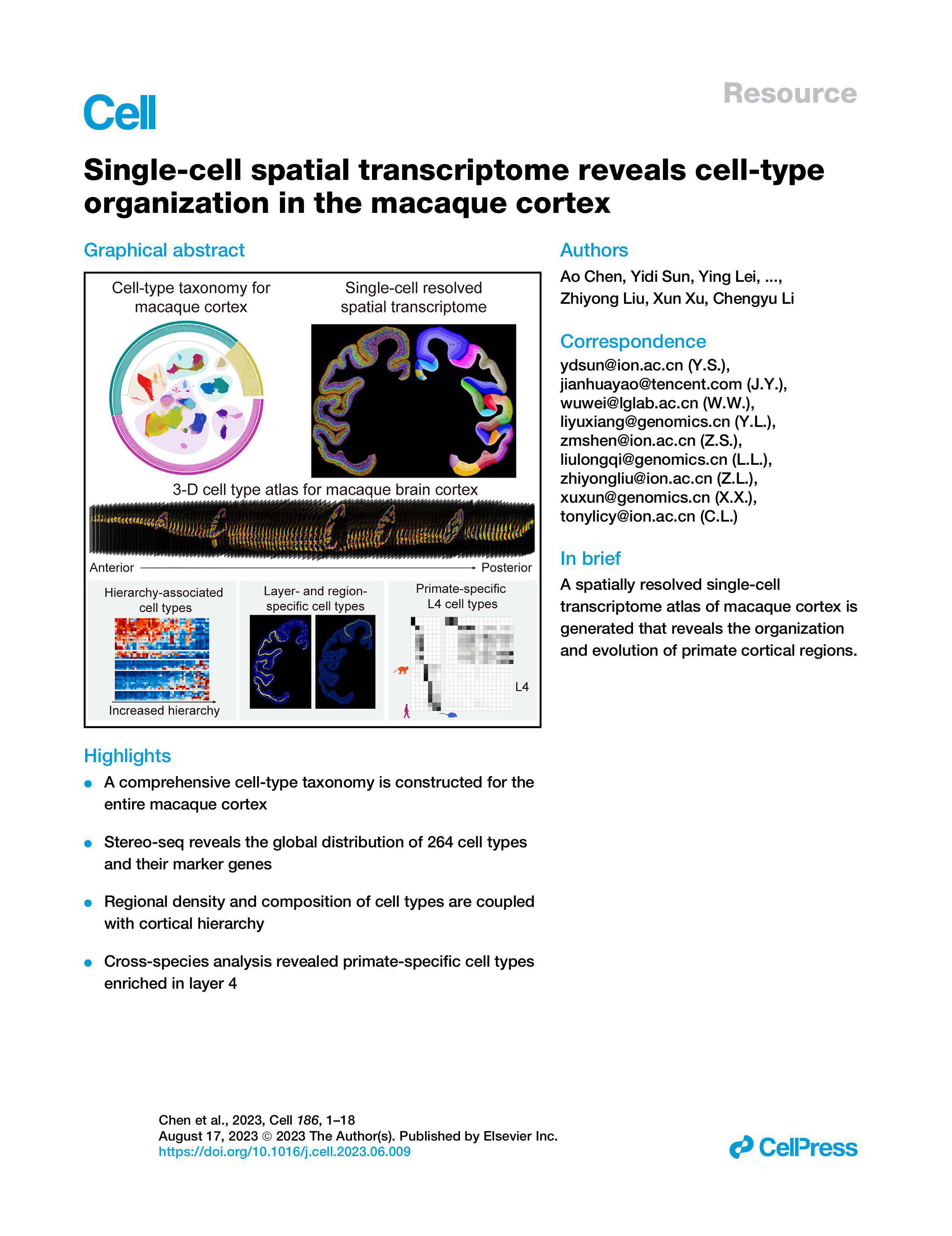
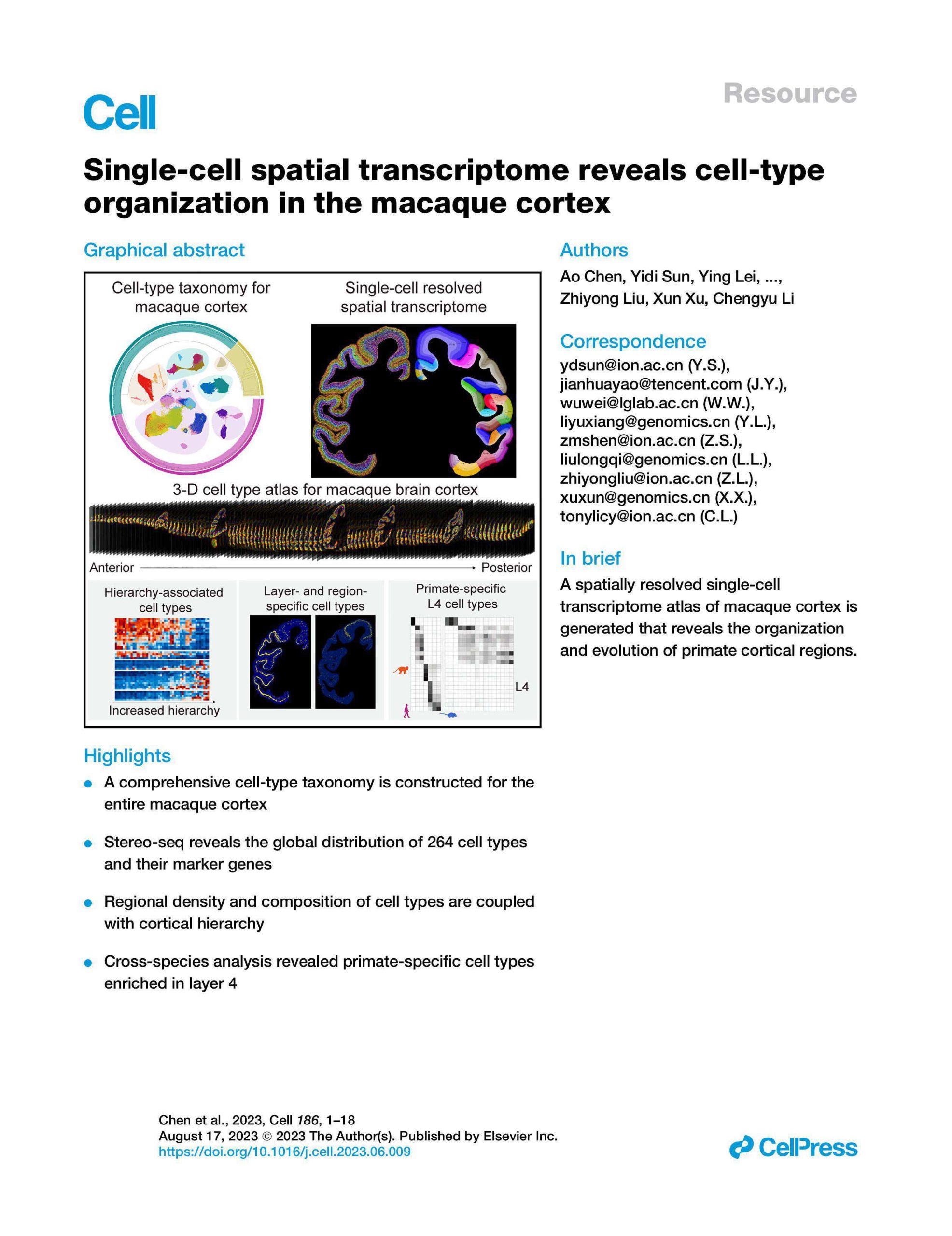
We must address two recurring, deeper issues that most papers skirt. First, traditional solutions assume uniform capture efficiency across a broadened surface; in truth, peripheral loss and gradient effects reduce effective sequencing depth at chip edges. Second, many manufacturers scale by array density alone—cramming more barcodes per square millimeter—without redesigning fluidic channels or cDNA synthesis pathways, which amplifies UMI collision and cross-talk. I observed this directly during a pilot in October 2020, when increasing array density by 35% without altering flow dynamics raised UMI duplication rates by nearly 12%. These are not abstract concerns; they are engineering and procurement failures that cost time and money. —I will not mince words: design decisions on spot geometry and channel routing are as consequential as reagent choice.

What went wrong in most large-array rollouts?
Forward-Looking Principles and Comparative Criteria for New Designs
Turning from fault-finding to constructive practice, I set forth comparative criteria that I use when evaluating any new stereo-seq large chip designs. First, ask for validated metrics on capture efficiency across the full chip area, not only in the central zone; demand heat-mapped read distributions. Second, compare barcode array topology—linear grids tend to be easier to correct for edge bias than radial or irregular matrices. Third, assess fluidic channel design and reagent contact time: modest increases in dwell time often yield disproportionate gains in cDNA yield. These criteria are practical; they reflect measurable trade-offs in throughput and data quality. I have benchmarked two suppliers in 2022 against these metrics and found a clear pattern: those who optimized fluidics reduced required sequencing depth by 15% on average. (Yes, that saving compounds.)
Let me be explicit about evaluation: include test runs with a defined control tissue, measure UMI collision rates, and chart sequencing depth versus mapped read percentage. Use these three metrics—edge uniformity, effective capture efficiency, and UMI collision rate—to compare candidate designs. I favor designs that report both empirical assays and engineering rationale; patents and glossy brochures mean little without numbers. We once rejected a promising chip because its edge uniformity fell below 85% in our acceptance test—this spared our client months of rework. Short note: adopt design reviews that include supply-chain timelines and spare-part lists; small vendors often cannot support rapid replacements.
What’s Next for Implementers?
For practitioners and wholesale buyers I counsel a measured, comparative approach. Procure small pilot batches, demand full-run heat maps, and insist on fluidic schematics. Evaluate vendors by the three metrics I listed—edge uniformity, capture efficiency, UMI collision rate—and score them against your lab’s throughput needs and sequencing budget. I speak as one who has negotiated contracts across Europe and Asia, and who has sat in instrument rooms at 02:00 to troubleshoot runs; these steps are neither academic nor optional. Consider also lifecycle support and the availability of validated protocols for your sample types—these determine whether a good chip becomes a good product in practice. In my view, measured choices today yield durable capacity tomorrow. I pause—then act.
To conclude with concrete advice: compare by those three metrics, run a controlled pilot, and secure vendor commitments on support response times. These are simple, measurable steps. For further consultation or vendor references, I point you to stomics—a practical contact I have engaged with in procurement discussions.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}